Android 线程池的使用
当我在 Android Studio 中使用如下方式
1 | new Thread(new Runnable() { |
创造线程时,编译器会报告如下警告: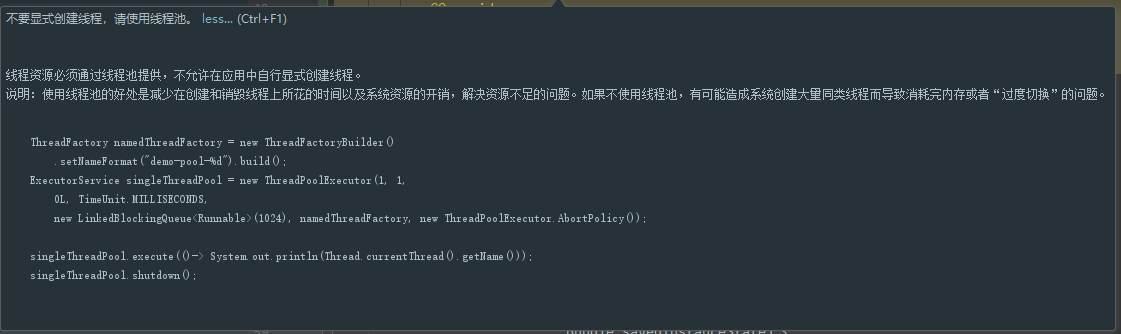
带着这些疑问,让我去学习了一下直接创造线程有什么缺点,及线程池的优点和使用。
使用new Thread()创造显式线程的缺点
- 在大量任务都在创建线程时,会频繁创建线程,而后这些线程使用完成之后又会被收回,导致频繁的GC,这种情况在多个列表 item 异步加载时极为常见;
- 多个线程之间互相竞争,缺乏统一的管理,降低了程序的运行效率,甚至卡顿;
- 当显式线程需要停止时,必须要保留每个线程的实例对象,在多个列表 item 异步加载时管理不便;
线程池
使用线程池可以给我们带来很多好处,首先通过线程池中线程的重用,减少创建和销毁线程的性能开销。其次,能控制线程池中的并发数,否则会因为大量的线程争夺 CPU 资源造成阻塞。最后,线程池能够对线程进行管理,比如使用 ScheduledThreadPool 来设置延迟N秒后执行任务,并且每隔 M 秒循环执行一次。
Android中常用的线程池都是通过对 ThreadPoolExecutor 进行不同配置来实现的,那么我们今天就从这这个 ThreadPoolExecutor 来开始吧!
ThreadPoolExecutor
ThreadPoolExecutor 的构造方法中各个参数如下:
1 | public ThreadPoolExecutor(int corePoolSize, |
corePoolSize:线程池中核心线程的数量;maximumPoolSize:线程池中最大线程数量;keepAliveTime:非核心线程的超时时长。当系统中非核心线程闲置时间超过keepAliveTime之后,则会被回收。如果ThreadPoolExecutor的allowCoreThreadTimeOut属性设置为true,则该参数也表示核心线程的超时时长;unit:非核心线程的超时时长参数的单位。有纳秒、微秒、毫秒、秒、分、时、天等.eg.TimeUnit.SECONDS、TimeUnit.MILLISECONDS;workQueue:线程池中的任务队列。该队列主要用来存储已经被提交但是尚未执行的任务。存储在这里的任务是由ThreadPoolExecutor的execute方法提交来的。workQueue 是一个 BlockingQueue 类型,BlockingQueue 是一个特殊的队列,当我们从 BlockingQueue 中取数据时,如果 BlockingQueue 是空的,则取数据的操作会进入到阻塞状态,当 BlockingQueue 中有了新数据时,这个取数据的操作又会被重新唤醒。同理,如果 BlockingQueue 中的数据已经满了,往 BlockingQueue 中存数据的操作又会进入阻塞状态,直到 BlockingQueue 中又有新的空间,存数据的操作又会被冲洗唤醒。
BlockingQueue 常用的实现类如下几种:
ArrayBlockingQueue:这个表示一个规定了大小的 BlockingQueue , ArrayBlockingQueue 的构造函数接受一个 int 类型的数据,该数据表示 BlockingQueue 的大小,存储在 ArrayBlockingQueue 中的元素按照 FIFO (先进先出)的方式来进行存取。LinkedBlockingQueue:这个表示一个大小不确定的 BlockingQueue ,在 LinkedBlockingQueue 的构造方法中可以传一个int类型的数据,这样创建出来的 LinkedBlockingQueue 是有大小的,也可以不传,不传的话, LinkedBlockingQueue 的大小就为 Integer.MAX_VALUE,源码如下:
1 | /** |
PriorityBlockingQueue:这个队列和LinkedBlockingQueue类似,不同的是PriorityBlockingQueue中的元素不是按照FIFO来排序的,而是按照元素的Comparator来决定存取顺序的(这个功能也反映了存入PriorityBlockingQueue中的数据必须实现了Comparator接口)。SynchronousQueue:这个是同步Queue,属于线程安全的BlockingQueue的一种,在SynchronousQueue中,生产者线程的插入操作必须要等待消费者线程的移除操作,Synchronous内部没有数据缓存空间,因此我们无法对SynchronousQueue进行读取或者遍历其中的数据,元素只有在你试图取走的时候才有可能存在。我们可以理解为生产者和消费者互相等待,等到对方之后然后再一起离开。
threadFactory:为线程池提供创建新线程的功能,这个我们一般使用默认即可handler:拒绝策略。当线程无法执行新任务时(一般是由于线程池中的线程数量已经达到最大数或者线程池关闭导致的),默认情况下,当线程池无法处理新线程时,会抛出一个RejectedExecutionException。
默认如下:
1 | public static class AbortPolicy implements RejectedExecutionHandler { |
以上则是线程池的构造参数的解释。
那么对于核心线程数和最大线程数,可以参考AsyncTask,如下所示:
1 | public abstract class AsyncTask<Params, Progress, Result> { |
核心线程数为手机 CPU 数 +1( CPU 数量获取方式Runtime.getRuntime().availableProcessors()),最大线程数为手机 CPU 数 × 2 + 1,线程队列的大小为 128
ThreadPoolExecutor 的执行规则
当任务提交到线程池中以后,则会按照一下规则进行处理:
execute 一个线程之后,如果线程池中的线程数未达到核心线程数,则会立马启用一个核心线程去执行;
execute 一个线程之后,如果线程池中的线程数已经达到核心线程数,且 workQueue 未满,则将新线程放入 workQueue 中等待执行;
execute 一个线程之后,如果线程池中的线程数已经达到核心线程数但未超过非核心线程数,且workQueue已满,则开启一个非核心线程来执行任务;
execute 一个线程之后,如果线程池中的线程数已经超过非核心线程数,则拒绝执行该任务;
系统配置的 ThreadPoolExecutor
- FixedThreadPool
FixedThreadPool是一个核心线程数量固定的线程池,创建方式如下:
1 | ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3); |
我们看到核心线程数和最大线程数一样,说明在 FixedThreadPool 中没有非核心线程,所有的线程都是核心线程,且线程的超时时间为0,说明核心线程即使在没有任务可执行的时候也不会被销毁(这样可让 FixedThreadPool 更快速的响应请求),最后的线程队列是一个 LinkedBlockingQueue ,但是 LinkedBlockingQueue 却没有参数,这说明线程队列的大小为 Integer.MAX_VALUE(2的31次方减1),OK,看完参数,我们大概也就知道了 FixedThreadPool 的工作特点了,当所有的核心线程都在执行任务的时候,新的任务只能进入线程队列中进行等待,直到有线程被空闲出来.
- SingleThreadExecutor
SingleThreadExecutor 和 FixedThreadPool 很像,不同的就是 SingleThreadExecutor 的核心线程数只有 1。
1 | public static ExecutorService newFixedThreadPool(int nThreads) { |
使用 SingleThreadExecutor 的一个最大好处就是可以避免我们去处理线程同步问题,其实如果我们把 FixedThreadPool 的参数传个1,效果就和SingleThreadExecutor一致了.
- CachedThreadPool
CachedTreadPool一个最大的优势是它可以根据程序的运行情况自动来调整线程池中的线程数量。
1 | public static ExecutorService newCachedThreadPool() { |
我们看到, CachedThreadPool 中是没有核心线程的,但是它的最大线程数却为 Integer.MAX_VALUE ,另外,它是有线程超时机制的,超时时间为60秒,这里它使用了 SynchronousQueue 作为线程队列, SynchronousQueue 的特点上文已经说过了,这里不再赘述。那么我们提交到 CachedThreadPool 消息队列中的任务在执行的过程中有什么特点呢?由于最大线程数为无限大,所以每当我们添加一个新任务进来的时候,如果线程池中有空闲的线程,则由该空闲的线程执行新任务,如果没有空闲线程,则创建新线程来执行任务。根据 CachedThreadPool 的特点,我们可以在有大量任务请求的时候使用 CachedThreadPool ,因为当 CachedThreadPool 中没有新任务的时候,它里边所有的线程都会因为超时而被终止。
- ScheduledThreadPool
ScheduledThreadPool是一个具有定时定期执行任务功能的线程池,源码如下:
1 | public ScheduledThreadPoolExecutor(int corePoolSize) { |
我们可以看到,它的核心线程数量是固定的(我们在构造的时候传入的),但是非核心线程是无穷大,当非核心线程闲置时,则会被立即回收。
使用ScheduledThreadPool时,我们可以通过如下几个方法来添加任务:
- 延迟启动任务
1 | public ScheduledFuture<?> schedule(Runnable command,long delay, TimeUnit unit); |
- 延迟定时执行循环任务
1 | public ScheduledFuture<?> schedule(Runnable command,long delay, TimeUnit unit); |
延迟 initialDelay 秒后每个 period 秒执行一次任务。
- 延迟执行任务
1 | public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, |
第一次延迟 initialDelay 秒,以后每次延迟 delay 秒执行一个任务。
ThreadPoolExecutor 其他常用功能
shutDown()关闭线程池,不影响已经提交的任务;shutDownNow()关闭线程池,并尝试去终止正在执行的线程;allowCoreThreadTimeOut(boolean value)允许核心线程闲置超时时被回收submit()- ThreadPoolExecutor 执行任务回调:
1 | @Override |
当线程池中的任务被执行的时候会回调此方法。